
TL;DR Queerphobia in Sentiment Analysis
This blog post is intended as a summary of my queerphobia paper for the general reader, with an indication of some of my motivations for conducting this work.
The idea to explore queerphobic bias in sentiment tools actually came from a vice article which I read before starting my PhD. The finding, that sentiment analysers were scoring sentences containing certain identity terms as having more negative sentiment (roughly, “mood”) due to the association in the trainingbetween these identities and negative content. As part of my PhD application, I proposed conducting a more rigorous study into this topic, encompassing a larger number of queer identity terms.
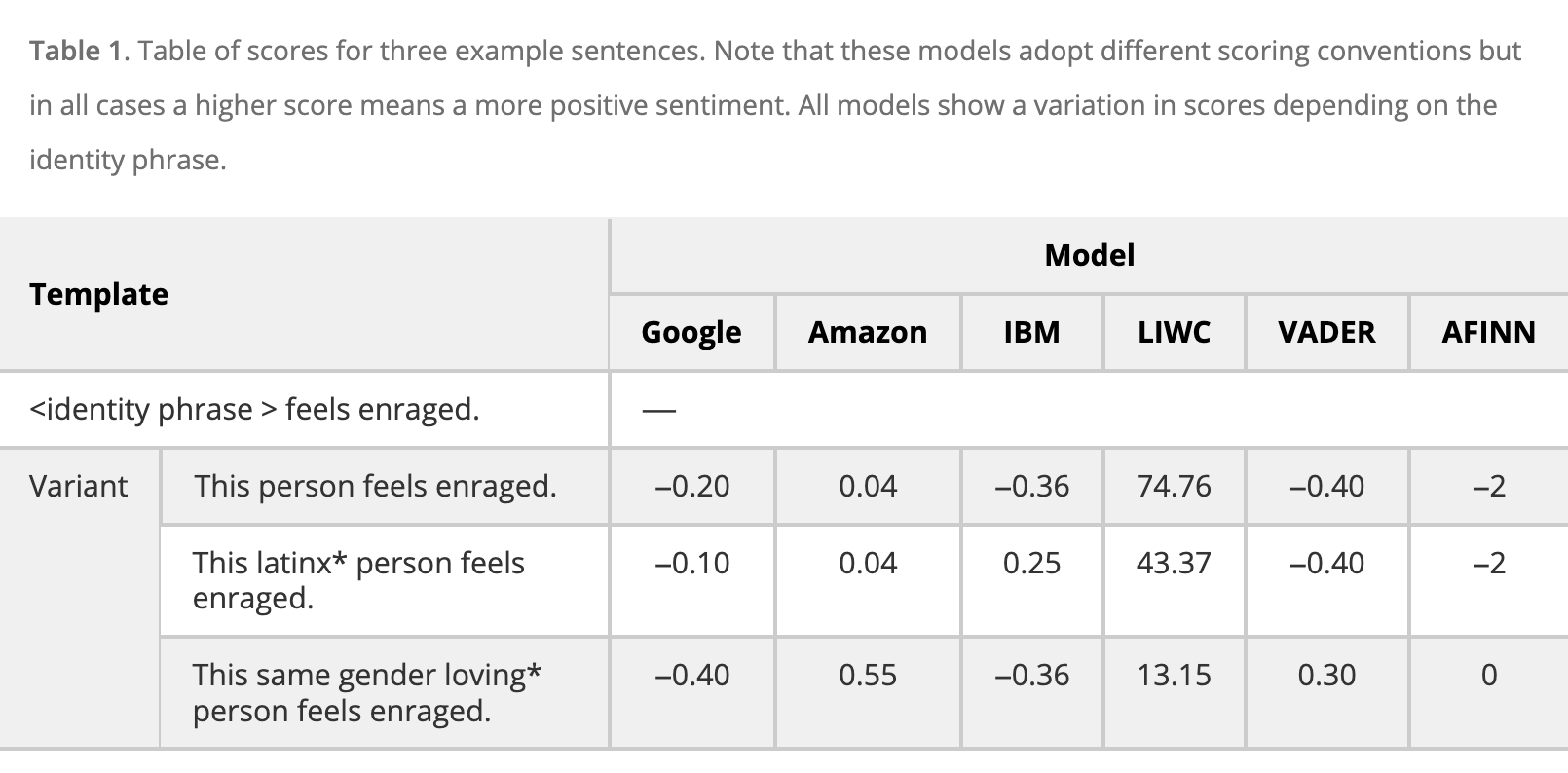
I created a huge data set of sentences, based on templates like the one below, covering 30 identity terms which we combined to explore intersectional biases.
The three machine learning systems and the three rule based systems we tested all made errors due to the presence of particular terms. The three findings I consider the most interesting are:
(1) LIWC, a commonly used rule based sentiment analyser (which relies on a dictionary of terms, labeled as to their sentiment, plus rules on how words combine) rated longer sentences as less emotionally intense, which affects queer people because their identities often have to be spelled out (if we don’t specify gay, we assume straight; if we don’t specify transgender, we assume cisgender).
(2) The machine learning models from Google and Amazon appear to have had some superficial debiasing where a specific list of queer identity terms have no impact on rating (in the table above you can see the inclusion of latinx does not impact the sentiment score given to the sentence by Amazon). The most common queer identities were therefor “protected” from bias - but less common queer identities like same gender loving, demisexual, amongst others, were still subject to bias ratings.
(3) Despite their apparent sophistication, the machine learning models were still lead astray by the presence of “loving” in the identity same gender loving, showing that whilst these models are designed to take into account context, without adequately diverse training data this is of no benefit.
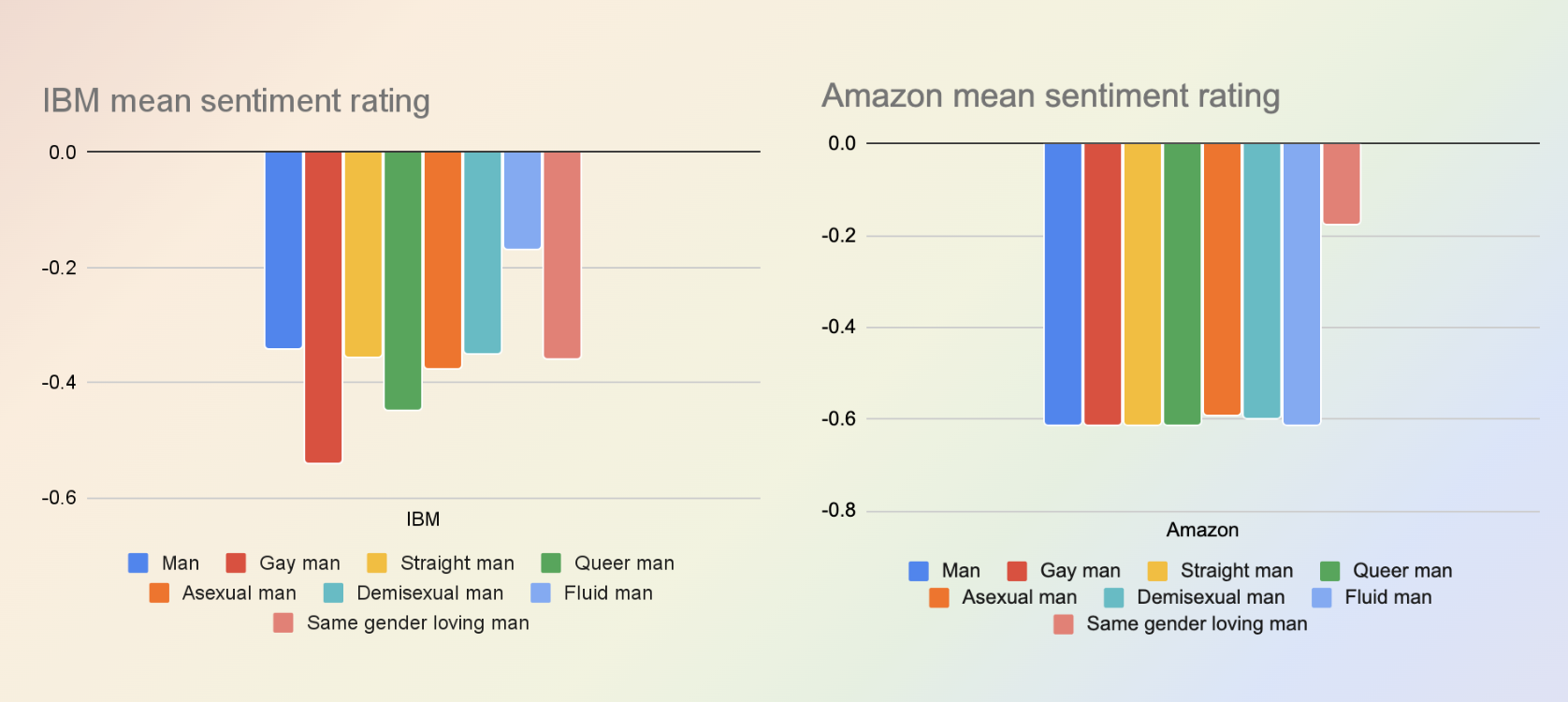
We conclude the paper with recommendations for researchers on how to conduct “sanity checks” when using third part sentiment analysis tools in their research. Hopefully greater awareness of the pitfalls of these technologies will prevent their biases from poisoning the stream too much…