
What’s in my big data? Transphobia
I have been using the AI2 API “What’s in My Big Data”1 to explore the types of content related to trans issues present in massive data sets used to train language and vision models. A major finding that will be shocking to approximately zero people is that there are large quantities of data using out-dated, inaccurate, offensive and dog-whistle-y2 language.
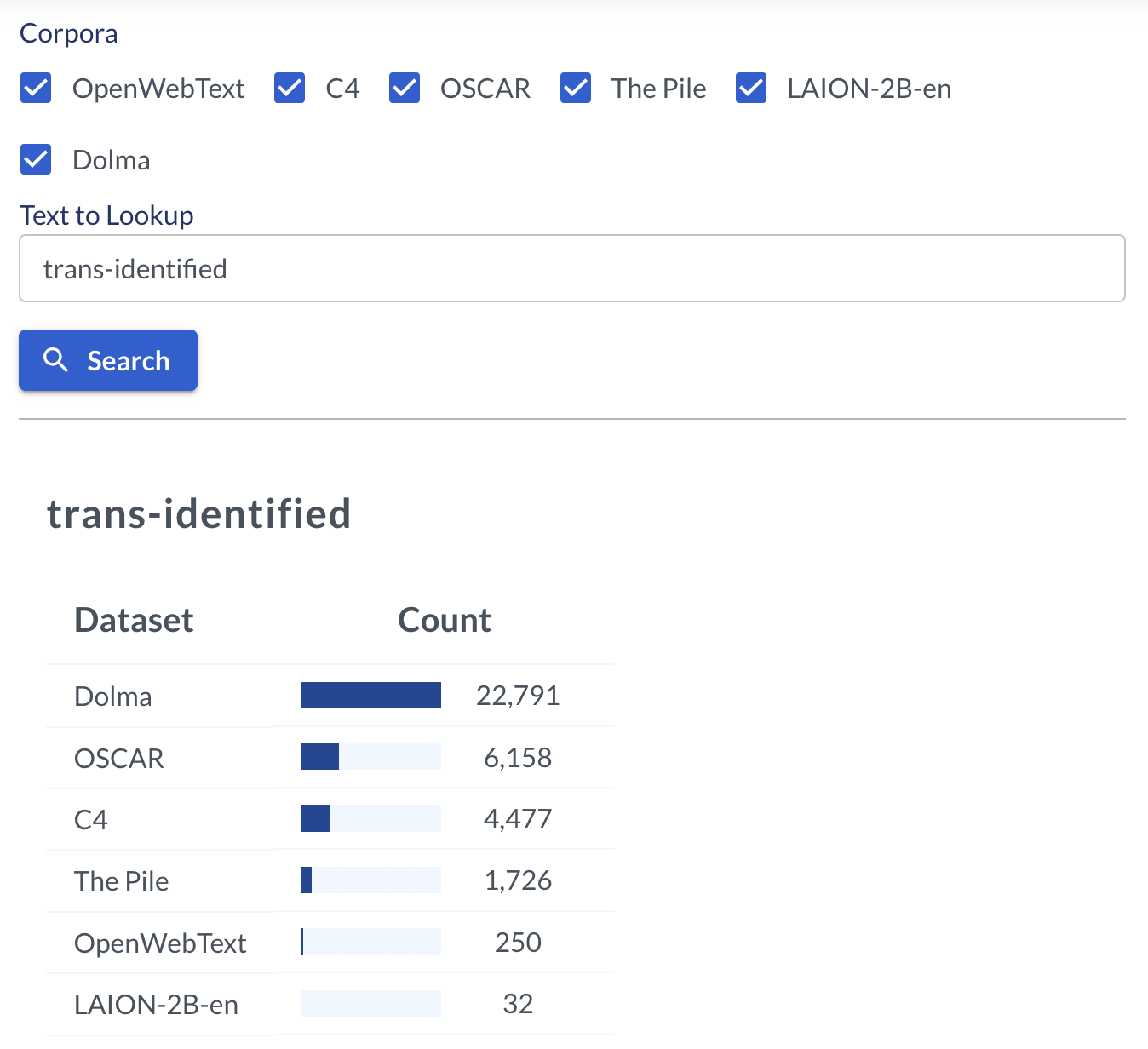
For example, the phrase “trans-identified” (a dog-whistle for transphobic “feminists” who believe people only claim to be trans in order to harm women) appears 32 times in the LAION data base. Images shared by people out to harm the trans commnity will have been selected to further their agenda, convincing the public that transgender people are at best guilty of mocking women and at worst a danger to society.
An image of a transgender woman may appear multiple times, variably captioned as “transgendered”, “trans identified” or even “tranny”. It seems plausible models may come to associate preferred and offensive identity terms in the encoding of the text, hence the issues identified in my paper even though preferred terms were used to generate images3.This may go some way to explaining the findings of my paper on the generation of images of non-cisgender people, particularly the tendency for the models to produce low quality, sexualised and stereotyping images.
Of course, this hits on a much wider issue that extends beyond just trans rights - the issue of the distance between data subject and data sharer. Specifically, it is often the case that the subject of an image or text found online was created and shared by someone outwith their community. For example, it is very likely that images of queer people, at Pride, in historic photos, celebrating their indigenous cultures etc are taken by and labeled by people from outside their community, who may through ignorance and malicious intentions label the data in an inaccurate or even offensive way. Thus the words associated with the identity are the words of the oppressor - and the association with the identity are the oppressor’s associations. For example, images of indigenous Americans may be shared by outsiders because they play into stereotypes of how indigenous people live - hence I found text-to-image models were incapable of producing images of two-spirit people at work conferences3, because traditional corporate jobs are not associated with indigenous people. I imagine that the ~2300 images captioned by “native woman” in the LAION data set similarly play into exotifying stereotypes.